
The University of Chicago
The University of Chicago
The University of Chicago
Toyota Technological Institute at Chicago
The University of Chicago
Toyota Technological Institute at Chicago
*Equal contribution
We present PROGRESSOR, a novel framework that learns a task-agnostic reward function from videos, enabling policy training through goal-conditioned reinforcement learning (RL) without manual supervision. Underlying this reward is an estimate of the distribution over task progress as a function of the current, initial, and goal observations that is learned in a self-supervised fashion. Crucially, PROGRESSOR refines rewards adversarially during online RL training by pushing back predictions for out-of-distribution observations, to mitigate distribution shift inherent in non-expert observations. Utilizing this progress prediction as a dense reward together with an adversarial push-back, we show that PROGRESSOR enables robots to learn complex behaviors without any external supervision. Pretrained on large-scale egocentric human video from EPIC-KITCHENS, PROGRESSOR requires no fine-tuning on in-domain task-specific data for generalization to real-robot offline RL under noisy demonstrations, outperforming contemporary methods that provide dense visual reward for robotic learning. Our findings highlight the potential of PROGRESSOR for scalable robotic applications where direct action labels and task-specific rewards are not readily available.
We propose to learn a unified reward model via an encoder that estimates the relative progress of an observation with respect to an initial observation and a goal observation , all of which are purely pixel-based.
We optimize our reward model to predict the distribution of the progress on expert trajectory. We use a shared visual encoder to compute the per-frame representation, followed by several MLPs to produce the final estimation:
We create the reward model by defining a function derived from the model’s predicted outputs given a sample of frame triplet () of trajectory as:
To tackle this distribution shift, we implement an adversarial online refinement strategy, which we refer to as “push-back”, that enables the reward model to differentiate between in- and out-of-distribution, . for a frame triplet sampled from and the estimated progress from , we update so that it learns to push-back the current estimation as with as the decay factor.
During online training, we fine-tune using hybrid objectives:
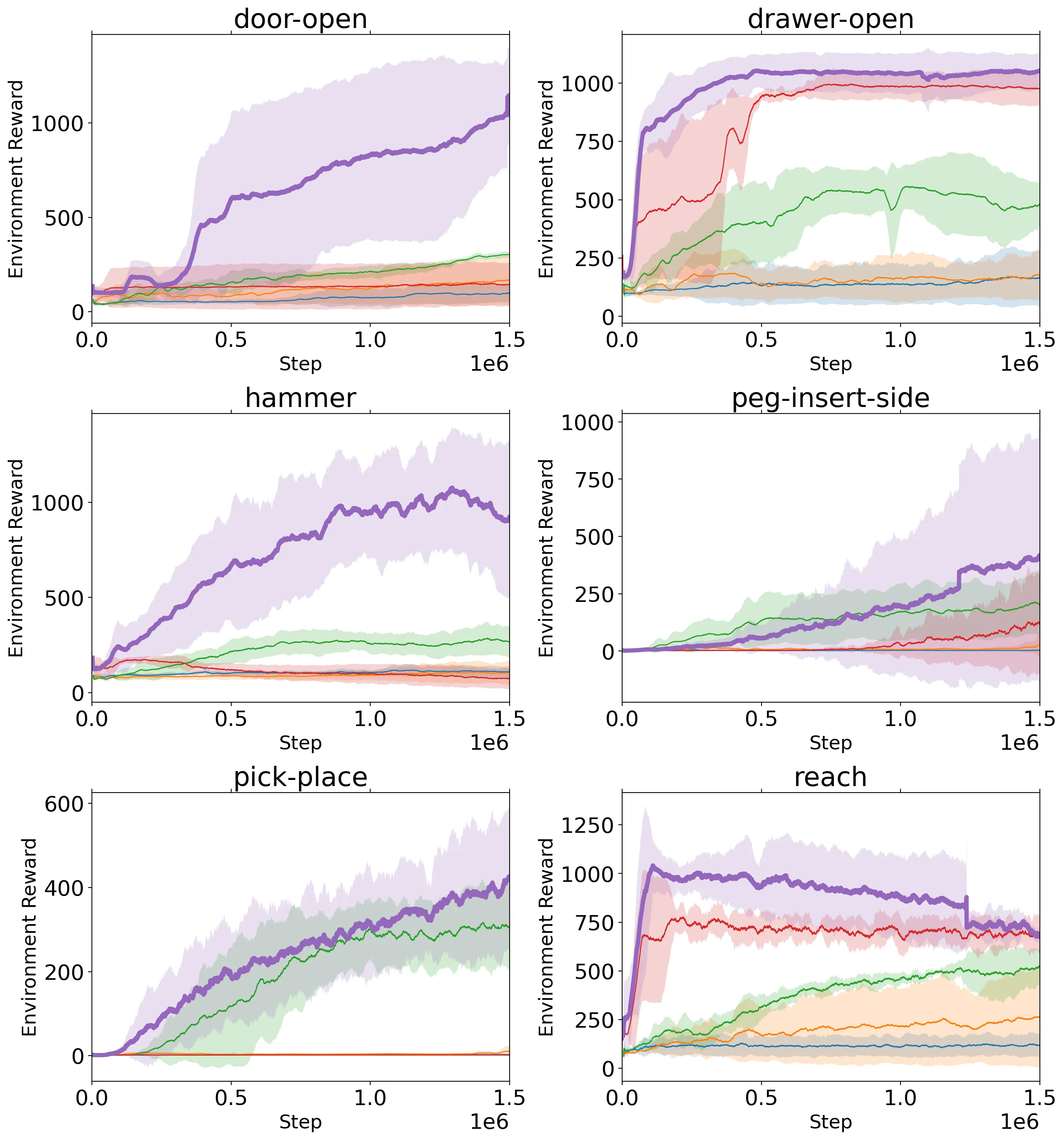
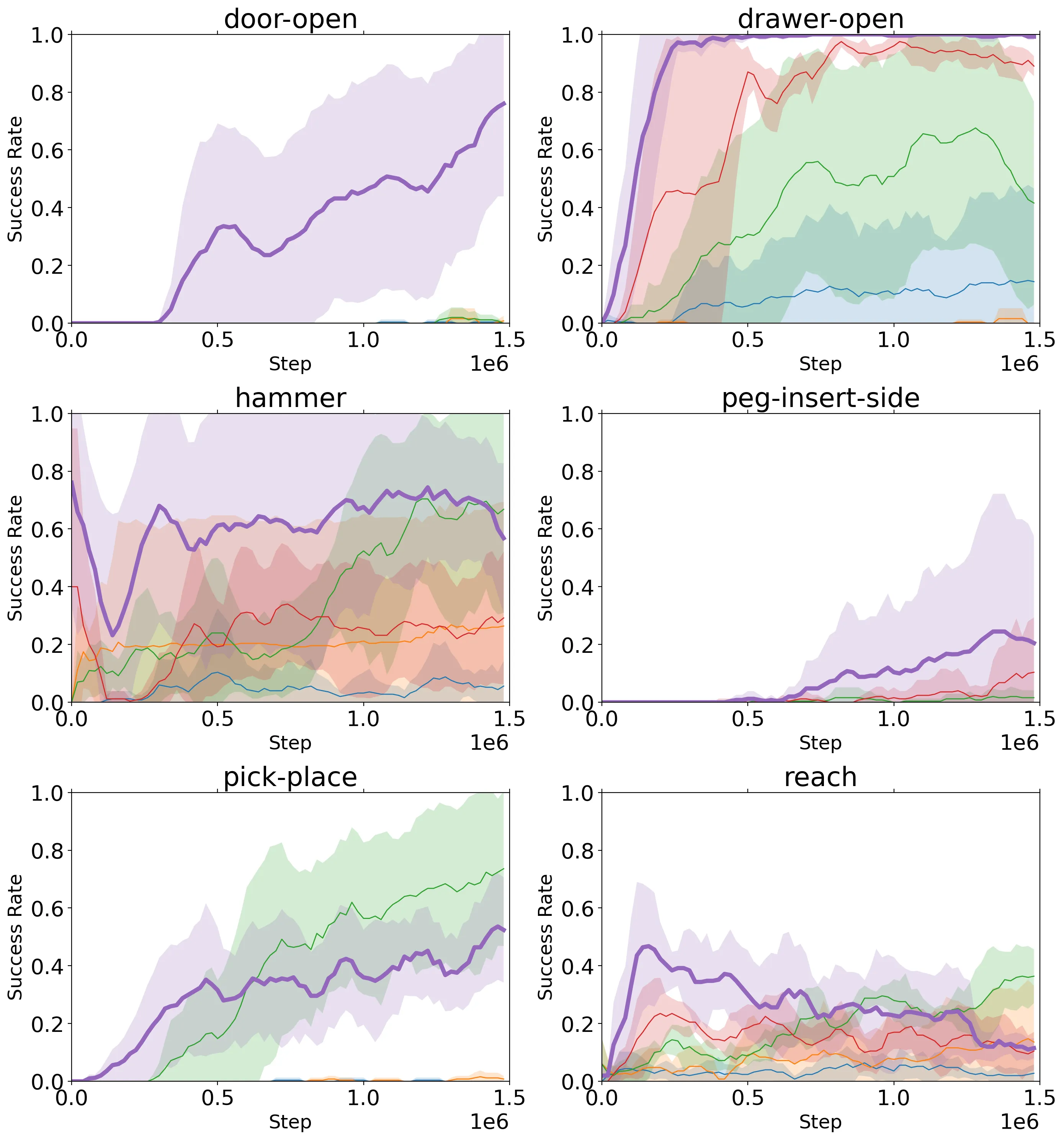
We evaluate the effectiveness with which PROGRESSOR learns reward functions from visual demonstrations that enable robots to perform various manipulation tasks in simulation as well as the real world.
In our simulated experiments, we used benchmark tasks from the Meta-World environment, selecting six table-top manipulation tasks: door-open, drawer-open, hammer, peg-insert-side, pick-place, and reach.

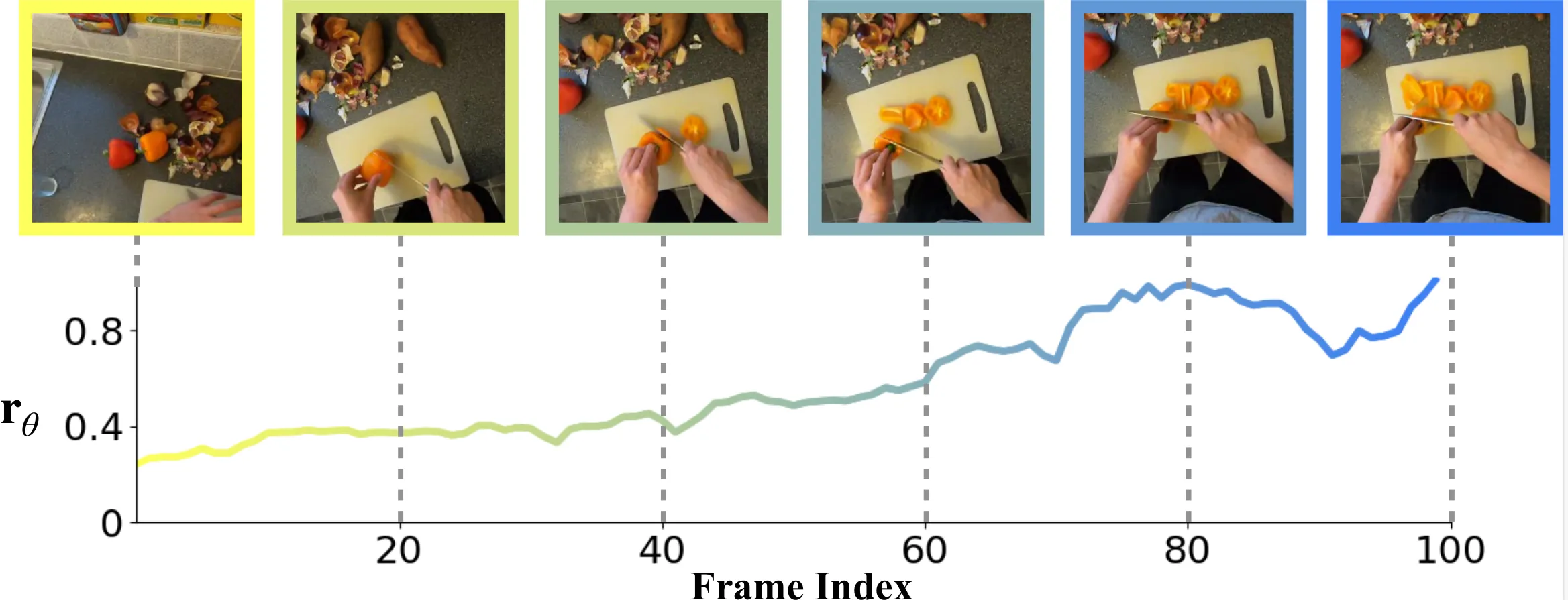
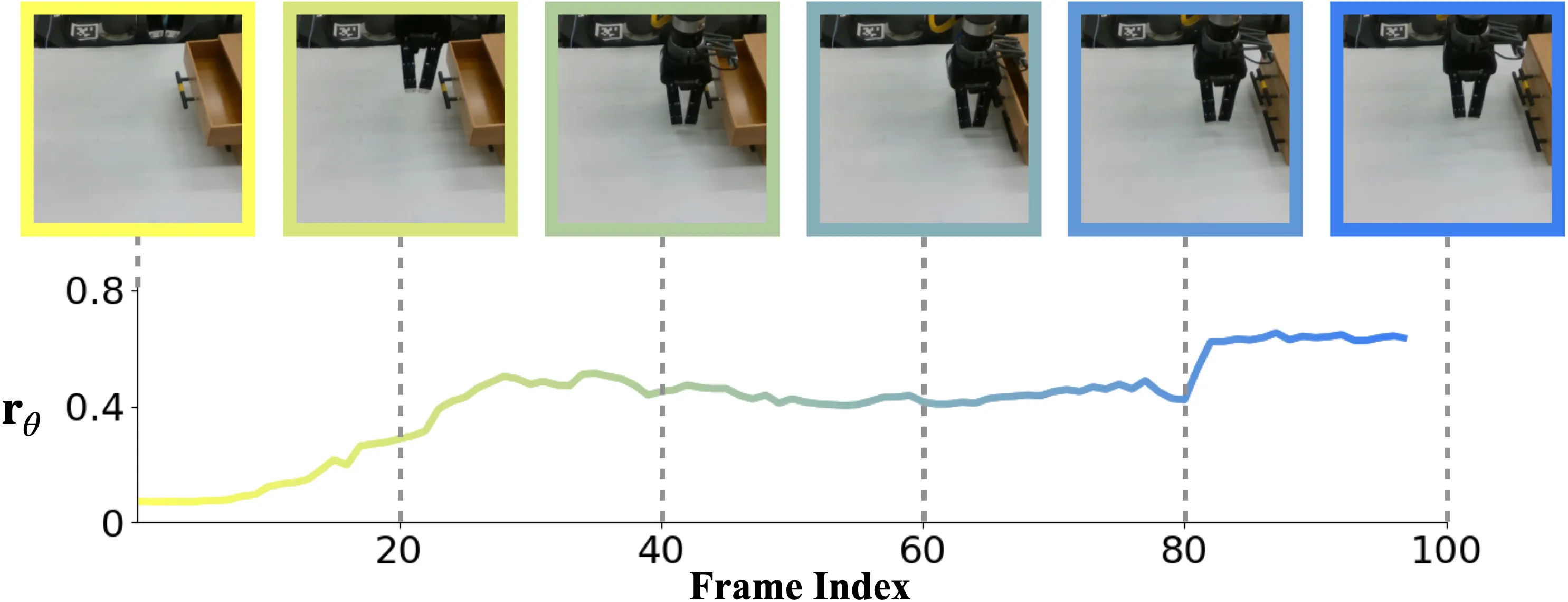
We randomly sample frame triplets triplet () from the videos ensuring a maximal frame gap .
We compare PROGRESSOR with R3M and VIP by freezing the pre-trained models and using them as reward prediction models to train RWR-ACT on downstream robotic learning tasks.
@inproceedings{ayalew2025progressor,
title={Progressor: A perceptually guided reward estimator with self-supervised online refinement},
author={Ayalew, Tewodros W and Zhang, Xiao and Wu, Kevin Yuanbo and Jiang, Tianchong and Maire, Michael and Walter, Matthew R},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={10297--10306},
year={2025}
}